
Khi quản lý một website, bạn chắc chắn muốn kiểm soát cách các công cụ tìm kiếm thu thập và lập chỉ mục dữ liệu của mình. Đây chính là lúc robots.txt phát huy tác dụng. Vậy, robots txt là gì và tại sao nó lại quan trọng? Đơn giản, đó là tệp hướng dẫn dành cho các bot, giúp bạn quyết định những phần nào trên website được phép hoặc không được phép thu thập.
Tuy nhiên, việc sử dụng robots.txt không chỉ dừng lại ở việc ngăn chặn bot mà còn hỗ trợ tối ưu hóa trải nghiệm tìm kiếm. Hãy cùng khám phá sâu hơn về tệp robots.txt và cách áp dụng nó hiệu quả ngay nhé!
Robots txt là gì?
Robots.txt là một tệp văn bản nằm trong thư mục gốc của một website, được sử dụng để hướng dẫn các công cụ tìm kiếm (search engine bots) về cách thu thập dữ liệu trên trang web đó. Nó cho phép bạn kiểm soát những phần của website mà các bot có thể hoặc không thể truy cập.
Vai trò của Robots txt
Robots.txt là yếu tố giúp bạn kiểm soát việc truy cập của các con bots và góp phần quan trọng trong việc tối ưu hóa website. Tệp robots.txt cho phép bạn điều chỉnh cách các công cụ tìm kiếm tương tác với website, từ việc bảo vệ thông tin đến việc cải thiện hiệu suất trang web.
Ngăn Chặn Nội Dung Trùng Lặp
Robots.txt có thể giúp bạn kiểm soát việc xuất hiện nội dung trùng lặp trên website. Khi các bots truy cập vào những phần không quan trọng hoặc không cần thiết (như các trang có nội dung trùng lặp), nó có thể làm giảm chất lượng và thứ hạng SEO của bạn.
Để tránh tình trạng này, bạn có thể sử dụng robots.txt để ngừng các bots thu thập những trang này, đảm bảo rằng chỉ những nội dung quan trọng và duy nhất được lập chỉ mục. Các lệnh như Meta Robot trong tệp robots.txt có thể là lựa chọn tốt để giải quyết vấn đề trùng lặp.
Giữ Các Phần Trang Ở Chế Độ Riêng Tư
Một trong những lợi ích lớn của robots.txt là khả năng bảo vệ các khu vực riêng tư trên trang web, chẳng hạn như các trang quản trị viên hoặc tài liệu nhạy cảm. Bằng cách chỉ định trong tệp robots.txt, bạn có thể đảm bảo rằng các bot không có quyền truy cập vào các khu vực không công khai của website, giúp bảo vệ dữ liệu cá nhân hoặc thông tin quan trọng.
Ngăn Các Trang Kết Quả Tìm Kiếm Nội Bộ Xuất Hiện trên SERP
Robots.txt cũng có thể giúp bạn kiểm soát sự hiển thị của các trang kết quả tìm kiếm nội bộ (search result pages) trên công cụ tìm kiếm. Thông qua việc ngừng lập chỉ mục những trang này, bạn ngăn chặn việc chúng xuất hiện trên kết quả tìm kiếm, từ đó giúp trang web của bạn giữ được sự sạch sẽ và chính xác khi hiển thị các kết quả tìm kiếm bên ngoài.
Chỉ Định Vị Trí của Sitemap
Robots.txt không chỉ giúp kiểm soát việc thu thập dữ liệu mà còn có thể được sử dụng để chỉ định vị trí của tệp Sitemap. Việc làm này giúp các công cụ tìm kiếm dễ dàng tìm thấy và lập chỉ mục các trang quan trọng của website, đặc biệt hữu ích cho các trang web có cấu trúc phức tạp hoặc nhiều nội dung.
Ngăn Các Công Cụ Của Google Index Một Số Tệp Nhất Định
Bạn cũng có thể sử dụng robots.txt để ngừng việc Google Index một số tệp nhất định, như hình ảnh, video hoặc tài liệu PDF. Bạn nên áp dụng khi không muốn những tệp này xuất hiện trong kết quả tìm kiếm nhưng vẫn muốn giữ chúng cho mục đích nội bộ hoặc chia sẻ với người dùng có quyền truy cập.
Sử Dụng Lệnh Crawl-delay Để Quản Lý Tốc Độ Thu Thập Dữ Liệu
Một tính năng đặc biệt của robots.txt là lệnh Crawl-delay, cho phép bạn chỉ định khoảng thời gian giữa các lần thu thập dữ liệu. Từ đó, máy chủ của bạn sẽ được giảm tải dữ liệu, đặc biệt khi có nhiều công cụ tìm kiếm truy cập vào website cùng lúc. Nói cách khác, website của bạn sẽ không bị quá tải và hoạt động ổn định ngay cả khi lưu lượng truy cập lớn.
3. Thành phần của Robots txt
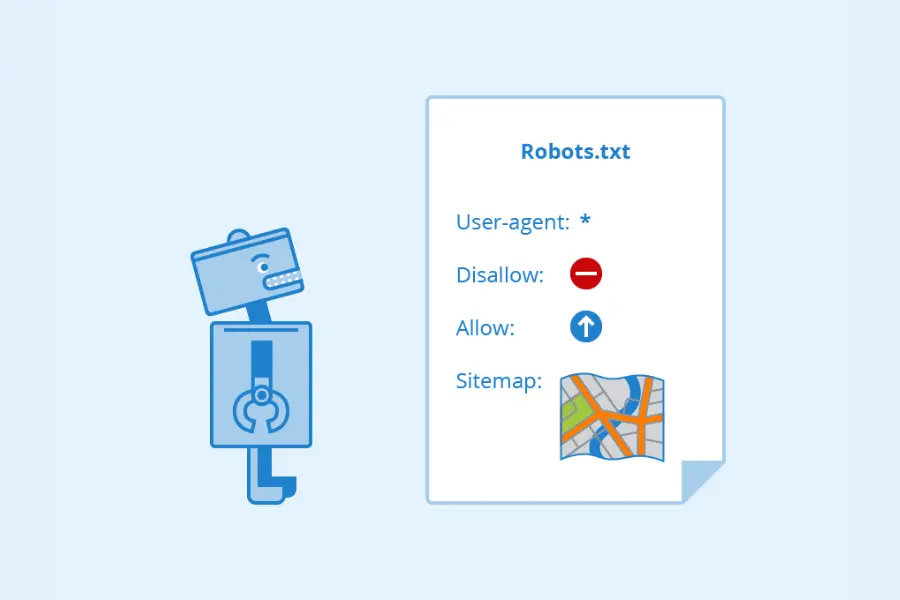
Tệp robots.txt bao gồm những thành phần chính để hướng dẫn các công cụ tìm kiếm cách thu thập dữ liệu trên trang web. Các thành phần đều được viết theo định dạng văn bản đơn giản, với cú pháp cụ thể để chỉ định quyền truy cập.
- User-agent xác định tên bot mà các quy tắc áp dụng, ví dụ như Googlebot hoặc có thể sử dụng dấu “” để áp dụng cho tất cả các bot.
- Disallow dùng để chặn bot không được truy cập vào các trang hoặc thư mục nhất định trên trang web, chẳng hạn như /admin/ để ngăn truy cập vào thư mục quản trị.
- Allow cho phép bot truy cập vào các tệp hoặc trang cụ thể ngay cả khi chúng nằm trong khu vực bị chặn bởi Disallow, ví dụ như /public/.
- Sitemap, nơi chỉ định vị trí của tệp sitemap để bot dễ dàng tìm thấy và thu thập thông tin từ những trang cần lập chỉ mục, thường được viết dưới dạng URL đầy đủ như https://www.example.com/sitemap.xml.
- Crawl-delay có thể được sử dụng để kiểm soát thời gian giữa các lần truy cập của bot, giúp tránh việc máy chủ bị quá tải, ví dụ đặt giá trị là 10 để yêu cầu mỗi lần truy cập cách nhau 10 giây.
4. Cơ chế hoạt động của Robots txt
Cách hoạt động của tệp robots.txt diễn ra theo các bước sau:
Bước 1: Bot tìm kiếm tệp robots.txt
Khi bot (công cụ tìm kiếm như Googlebot) truy cập vào website, nó sẽ tìm tệp robots.txt nằm ở thư mục gốc của trang web (ví dụ: www.example.com/robots.txt).
Bước 2: Đọc và phân tích tệp robots.txt
Bot đọc nội dung tệp để hiểu các quy tắc. Nó xác định thông qua chỉ thị User-agent xem quy tắc có áp dụng cho mình hay không, sau đó tuân thủ hướng dẫn từ các lệnh như Disallow hoặc Allow.
Bước 3: Bắt đầu “Crawl” (thu thập dữ liệu)
Bot tiến hành thu thập dữ liệu từ website. Dựa trên hướng dẫn trong robots.txt, nó sẽ biết khu vực nào được phép truy cập và khu vực nào bị chặn. Quá trình thu thập còn được gọi là “Spidering”, khi bot di chuyển từ liên kết này sang liên kết khác để phân tích dữ liệu.
Bước 4: Tiến hành lập chỉ mục (Indexing)
Sau khi thu thập dữ liệu, bot lập chỉ mục nội dung để phục vụ cho các kết quả tìm kiếm của người dùng. Tệp robots.txt giúp chỉ định nội dung nào nên hoặc không nên xuất hiện trong chỉ mục.
Lưu ý:
Nếu tệp robots.txt không tồn tại hoặc không có bất kỳ chỉ thị nào cho User-agent, bot sẽ mặc định thu thập tất cả thông tin trên website. Tuy nhiên, tệp robots.txt chỉ đưa ra hướng dẫn; các bot không tuân thủ (như bot độc hại) vẫn có thể bỏ qua các chỉ thị này.
5. Một số lưu ý hạn chế về Robots txt
Dù tệp robots.txt hữu ích trong việc quản lý truy cập của bot, nó vẫn có một số hạn chế như sau:
- Không phải mọi bot đều tuân thủ: Một số công cụ tìm kiếm hoặc bot độc hại có thể bỏ qua tệp robots.txt và thu thập dữ liệu trái phép.
- Cách hiểu cú pháp khác nhau: Các trình thu thập dữ liệu có thể xử lý cú pháp trong robots.txt không đồng nhất, dẫn đến những hiểu lầm hoặc sai lệch trong việc áp dụng các chỉ thị.
- Không ngăn chặn hoàn toàn việc lập chỉ mục: URL bị chặn vẫn có thể được Google hoặc các công cụ tìm kiếm khác lập chỉ mục nếu có các liên kết từ những trang web khác dẫn đến URL đó.
Kết luận
Như vậy, robots.txt là gì và cách nó giúp kiểm soát việc thu thập dữ liệu trên website đã được làm rõ trong bài viết này. Đây là một công cụ quan trọng để đảm bảo rằng các bot chỉ truy cập vào những phần cần thiết của trang web. Tuy nhiên, để đạt được hiệu quả tối ưu, bạn cần kết hợp robots.txt với các chiến lược khác.






